Aurora Networks™ (ANS) and RUCKUS® Networks are now Vistance™ Networks
Visit their new site for all products and content
Aurora Networks™ (ANS) and RUCKUS® Networks are now Vistance™ Networks
Visit their new site for all products and content

Fiber-optic shuffle architecture is gaining currency as the go-to method to increase bandwidth and improve load balancing in AI factories. But what shuffle architecture, how does it work, and how can data centers implement it?
Data centers, particularly AI factories, are locked in a race to increase performance, speed and efficiency across their networks. Infrastructure is evolving at a dizzying pace, and while the front lines are in hyperscale AI data centers, the innovations that drive them forward are quickly finding broader adoption downstream, in neocloud, enterprise, multi-tenant and central office data center applications, including those at the edge of the network, where low-latency AI applications are increasingly common.
However, this pursuit of ever-greater bandwidth has finally started to hit a hard limit in the number of ports available per switch on standard Ethernet architecture—or has it?
Enter fiber-optic shuffle (sometimes mistakenly called “mesh”) architecture—an architecture that unlocks a new level of switch port density, reduces network congestion and increases reliability of expanding GPU clusters to both boost bandwidth and reduce network latency.
In data centers, each node communicates with every other node to process information. The speed and efficiency of this connection is what determines how quickly, reliably and cost-efficiently (from a latency point of view) data packets are transported. When demand on network bandwidth is high due to long-lived, high-volume data transmissions, sometimes referred to as “Elephant Flows,” it can result in network congestion and performance degradation. This degradation can be attributed to the network switch buffers becoming quickly overloaded by these long flows; this results in dropped packets, job stalling and can lead to the blocking of more sensitive or urgent traffic which cannot pass a layer of switches to reach its target node. In this scenario, the AI network will request a retransmission of the packets creating extra load on the network (consuming more power per token being processed) and new delays in job processing time—both of which are highly undesirable.
A shuffle architecture enables higher switching capacities at the network layers by evenly distributing traffic across multiple physical paths that are embedded into multiple discrete switching planes. Instead of connecting all of the optical lanes from a single GPU port to a single switch port in a single fabric—as is found in a traditional leaf and spine architecture—optical lane shuffling distributes each of the transmit lanes from a single GPU port across multiple leaf switches and multiple switched planes. Since a single switched port at the leaf layer is no longer dedicated to a single GPU port at the node, higher GPU count clusters can be enabled with just two tiers of switching without having to move to a three-tier model, with the net result being flatter network designs and a lower latency cost penalty.
The image below shows an example of a 400G GPU port using 4 x 100G Tx lanes. Each leaf switch port still receives 400G of bandwidth from the GPU layer, but with the 100G lanes coming from multiple GPUs (shown with color coding).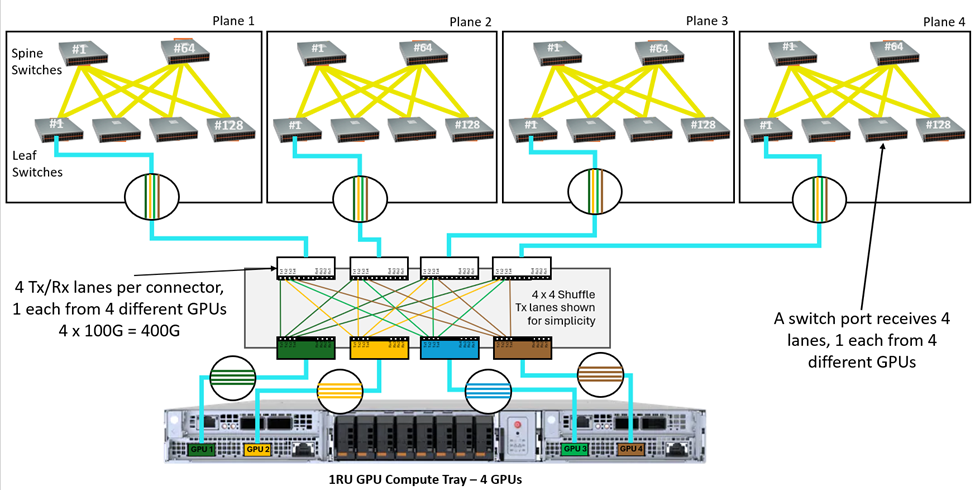
Distributing optical lanes from each GPU across multiple switch ports enables true multi-pathing from one GPU to another, enabling improved load balancing as traffic can now be spread across multiple planes and switch ports. Shuffling supports higher sustained throughput of larger AI workloads, since there is no longer a dependence on a single fiber channel or switch port. Also, if there is a switch or port failure, the network stays up. Three quarters of the workload is rerouted to the optimal physical path; only the affected ports operate at a reduced throughput.
Optical shuffling can be achieved via a number of different solutions, including shuffle modules, shuffle panels or shuffle cables. The choice of solution is driven by the architectural requirements of the AI network being deployed. CommScope offers our Propel™ shuffle modules, which I find offers the optimal best balance of performance and flexibility for most AI data center applications.
Led by AI factory applications, shuffle architectures are currently unlocking the next level of network density in data centers of all kinds. CommScope is proud to partner with data center operators worldwide to offer these and other state-of-the-art fiber infrastructure solutions. To see how we can help your data center evolve, I encourage you to reach out to your CommScope representative—or locate your representative here.
© 2026 CommScope Technologies LLC, an Amphenol company. All rights reserved. CommScope and the CommScope logo are registered trademarks of CommScope and/or its affiliates in the U.S. and other countries. For additional trademark information see https://www.commscope.com/trademarks. All product names, trademarks and registered trademarks are property of their respective owners.





